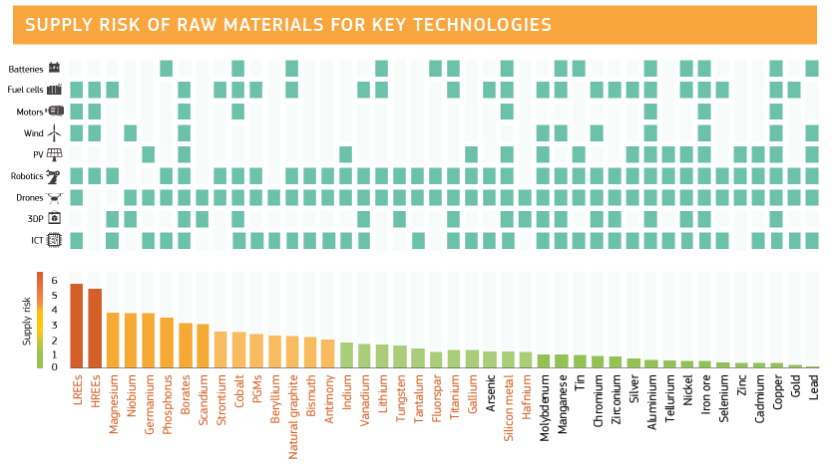
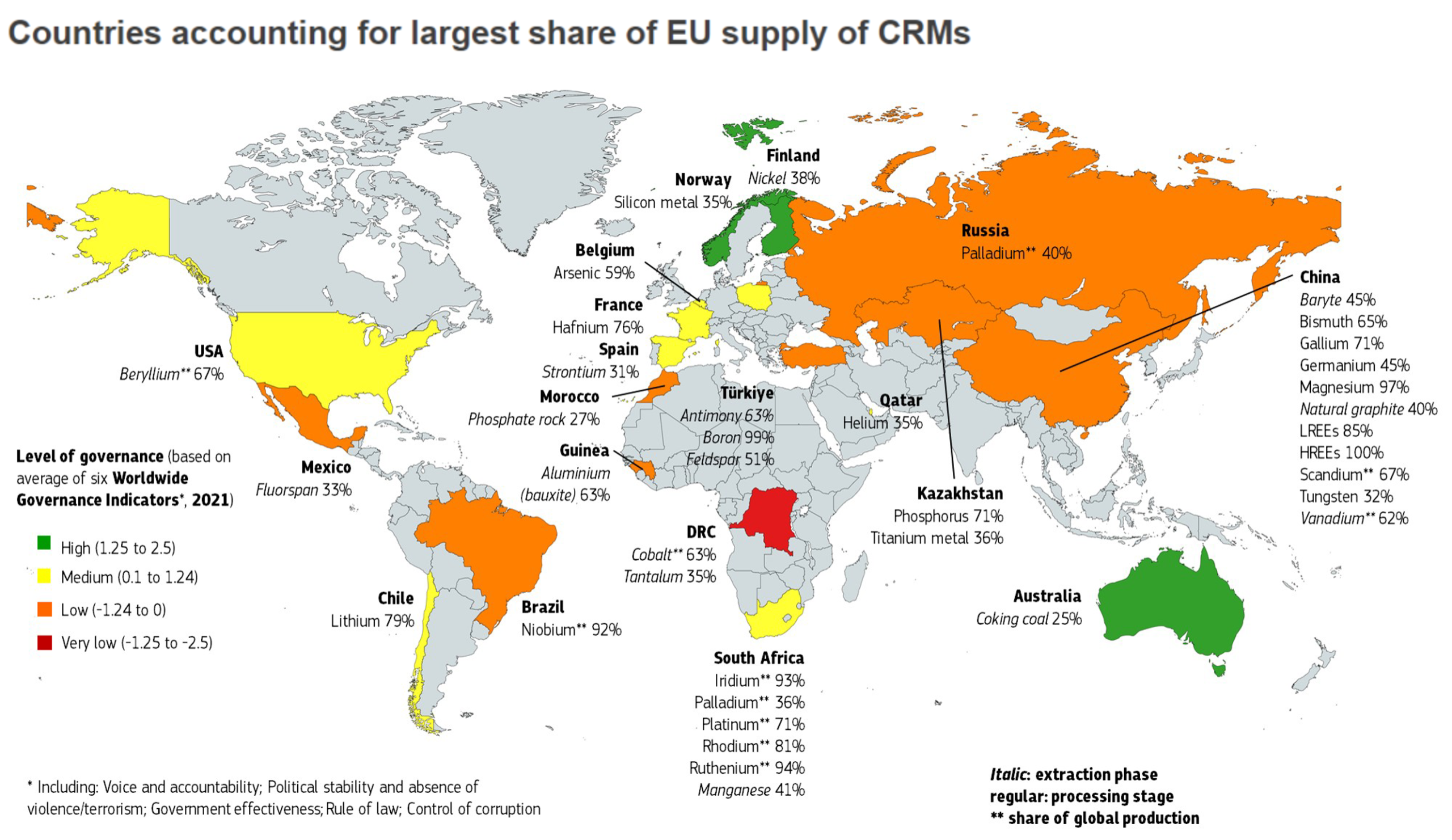
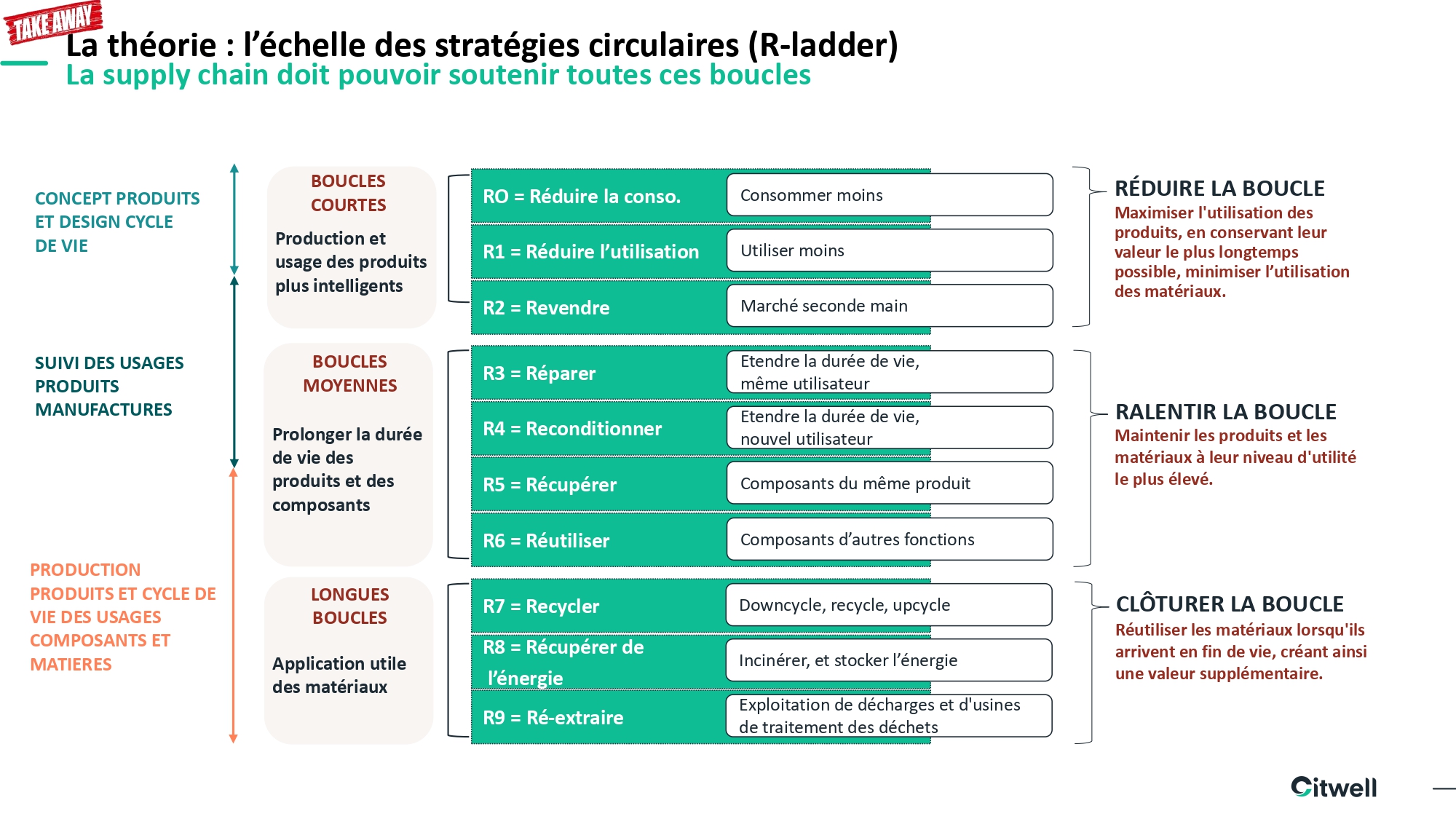
Gouvernance de la data : les piliers d’une transformation organisationnelle
«Je ne suis pas spécialiste de la data, c’est pas mon problème», «Y a tellement d’outils, je ne sais pas où trouver mes données clients», «La confiance est une des valeurs de notre entreprise, on n’a pas besoin d’une usine à gaz d’autorisations». Souvent entendues en entreprise, ces phrases reflètent une réalité : la donnée est largement discutée, mais sa gestion reste souvent dispersée. Nous avons donc décidé avec notre partenaire Citwell de dédier un webinar au sujet car il peut coûter cher à une entreprise. Voici le résumé de ce live qui vous permettra de comprendre les piliers de cette véritable organisation d’entreprise au travers d’exemples terrain et de nombreuses recommandations d’experts.
Rôles et responsabilités
Qui est responsable de quoi ?
Lors de ce webinar, Saâd Kadioui, Partner / Head of IS transformation chez Citwell a insisté sur le fait que le métier est le principal responsable de la qualité de la donnée. Il alerte les organisations qui diluent cette responsabilité en la confiant à un service de saisie sans valeur ajoutée «le vrai impact de ce genre d’organisation, c’est que ça dilue la responsabilité de la qualité de la donnée. Le métier ne se sent pas responsable, parce que ce n’est pas lui qui saisit, et le service qui saisit les données, il n’est pas responsable non plus, parce que ce n’est pas lui qui fournit la donnée.»
Pour structurer la gouvernance, il a introduit les rôles clés : le Data Owner, une personne du métier responsable du contenu et de la qualité d’une donnée, et le Data Steward, qui anime les processus de création et de modification. Le tout est orchestré par un Chief Data Officer.

Le rôle de data owner peut être cumulé avec d’autres fonctions, c’est le cas dans la plupart des entreprises.
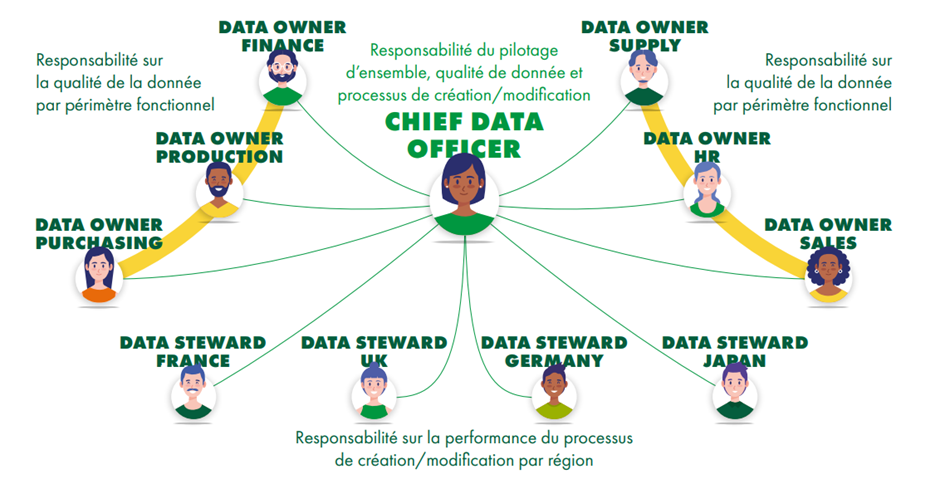
Illustration d’une organisation autour de la donnée
Olivier Weiss, S&OP Business Development Manager chez Renault, quant à lui a illustré ce point avec l’exemple des codifications de véhicules chez Renault Trucks, où la coexistence d’anciens et de nouveaux codes peut créer des erreurs si le métier n’assure pas la fiabilité, «dans la codification actuelle à 7 digits, chaque digit est signifiant et nous permet d’identifier le type de silhouette, la typologie de moteur, la typologie de norme d’émission, etc. Sauf que certains anciens codes modèles subsistent et si on emploie la nouvelle codification avec cette ancienne codification de modèles, on arrive à des données erronées». La responsabilité ou la proximité avec le métier est ici essentielle parce que c’est le métier qui va pouvoir dire «là, attention, on a un écart potentiel».

Mettre en place une collaboration étroite entre le métier et son Data Steward : le code douanier (carte d’identité du produit qui sert à traverser les frontières) est une donnée stratégique liée à 375 réglementations dont la gestion est évolutive (le Code Mondial des Douanes est modifié tous les 5 ans) : «Imaginez le nombre de données qu’il faut gérer et qui soient associées à ce code douanier. Si je n’ai pas l’appui d’un data steward pour mettre à jour ces données, ça devient quelque chose de très compliqué pour moi», conclu Delphine Cuvellier Customs manager France chez Alstom
Cartographie des données
Où trouver la donnée et qui en est propriétaire ?
Face à la multiplicité des outils (ERP, PLM, etc.), le besoin d’un “GPS de la donnée” se fait sentir. Saad a expliqué qu’il n’existe pas d’urbanisation (cartographie de la donnée) idéale universelle, mais une qui soit adaptée au contexte et aux usages de chaque entreprise. La clé est de définir où la donnée doit être créée, modifiée et stockée, en respectant une relation maître-esclave stricte (un seul maître pour la modification, plusieurs esclaves pour la consultation) afin de garantir l’intégrité.
Rappelons que dans l’urbanisation, il faut d’abord réfléchir aux usages et à la complexité d’usage, « par exemple, si je suis dans une entreprise qui produit des pièces d’usinage standard, avec peu de documentation, des cycles de vie produits qui sont hyper lents, et bien je n’ai peut-être pas besoin d’un PLM (Product Lifestyle Management), et peut-être que pour les nouveaux produits que je crée, un workflow ERP pourrait suffire. »

Toujours évaluer le rapport bénéfice/coût d’obtention d’une donnée : « il y a des données qui sont très facilement accessibles et d’autres pour lesquelles le coût peut être parfois extrêmement élevé. Cela peut être dû à l’histoire des systèmes avec lesquels on a travaillé, à la non-qualité ou à la non complétude des saisies d’alors. Donc il faut toujours se poser la question de l’utilité business in fine ».
Sécurité des données
Quel est le niveau de confidentialité de ma donnée et comment la protéger ?
Les intervenants ont abordé la nécessité de sécuriser l’accès aux données. Saad a préconisé de trouver un équilibre pragmatique dans la gestion des accès pour ne pas créer une “usine à gaz”, tout en soulignant les risques immenses (fuites de données, perte d’intégrité, non-conformité RGPD) d’une gestion laxiste, notamment lors des go-lives de projets, «ce qui va vraiment nous pousser à être pragmatique là-dedans, c’est le niveau de maintenabilité et de confidentialité.»
Olivier a partagé un exemple dans lequel le croisement d’un numéro de châssis avec des données de géolocalisation flirte avec la notion de donnée personnelle, «Tous les véhicules sont connectés, on reçoit des informations sur les trajets, les immatriculations, c’est une source de business importante. Est-ce que je ne pourrais pas identifier le conducteur ? Des données sensibles peuvent se nicher à des niveaux qu’on ne soupçonne pas nécessairement.»

L’avènement de la BI et de l’IA (LLMs) a considérablement augmenté l’exposition au risque, « on connaît tous la valeur de la donnée, il y a beaucoup de hackers qui cherchent ces données-là et il y a des capacités à les diffuser encore plus fortes. Donc, il faut un modèle de restriction d’accès à la donnée construit et robuste ». Pour cela, Delphine recommande l’utilisation d’un RACI pour clarifier les responsabilités et les accès.
Processus de gestion des données
Quelles données sont obligatoires versus optionnelles ?
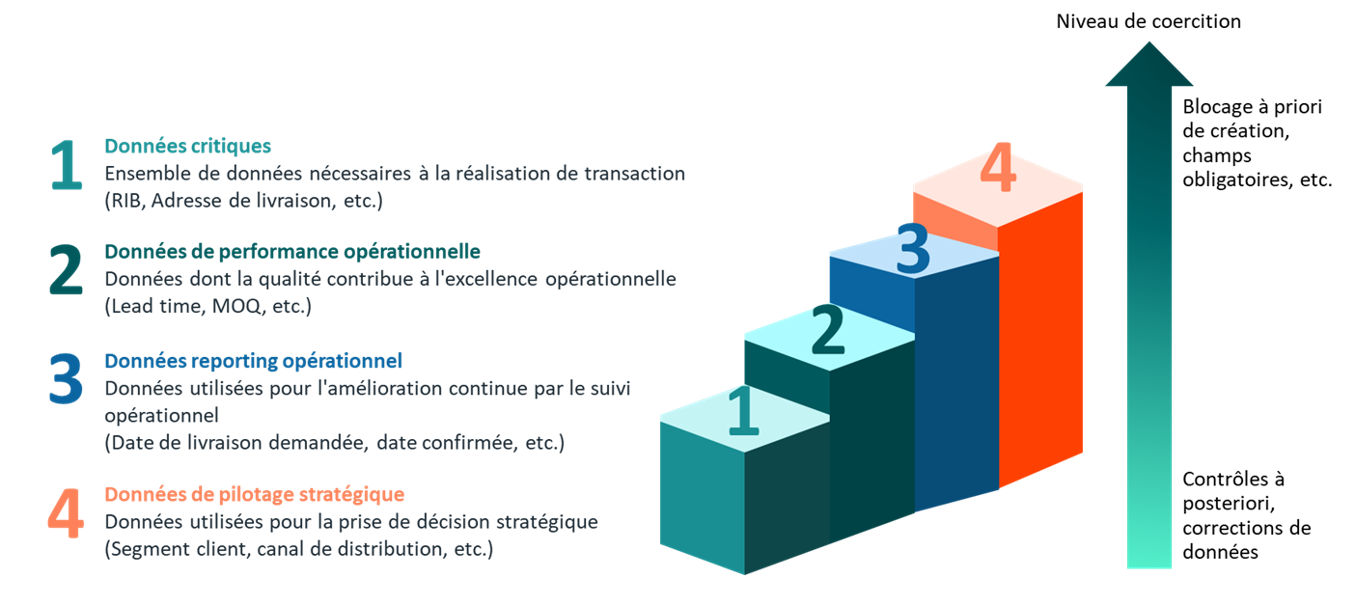
Pour contrer le recours aux fichiers Excel parallèles par manque de confiance dans les systèmes, il est crucial de gérer le cycle de vie de la donnée (création, vie, mort) via des processus robustes et documentés. Saad a insisté sur la “frugalité” : structurer et maintenir en qualité uniquement les données dont la valeur pour le business dépasse le coût de gestion.
Pour ce faire, il a introduit la distinction entre les contrôles à priori (bloquants, pour garantir la qualité) et à posteriori (non bloquants, pour la fluidité). L’application de ces contrôles dépend de la criticité de la donnée, classée en quatre groupes : données critiques, de performance opérationnelle, de reporting et de pilotage stratégique.

La qualité des données doit être orchestrée, elle est intimement liée au processus et à l’implication des responsables et des animateurs, notamment pour les master data transverses (articles clients, fournisseurs, etc.). Dès lors, «pour augmenter la robustesse des données, leur qualité, il faut les cadrer en création et en modification, et puis ne pas altérer l’efficacité opérationnelle, avec des temps de cycle qui seraient trop longs entre le besoin de création et la disponibilité de la donnée dans le système.»
Anticiper les données et savoir à quel moment elles sont critiques et stratégiques, c’est ce qu’il y a de plus important pour fluidifier une supply chain.
Quid de la performance ?
Le contrôle et l’assurance de la performance de la gouvernance des données s’articulent autour de deux axes principaux :
-
 La responsabilité d’animation
La responsabilité d’animation -
 La responsabilité de contenu
La responsabilité de contenu
D’un côté, l’animation vise à garantir la qualité, la rapidité de disponibilité et l’exactitude des données dès leur première production. Les indicateurs clés (KPI) associés sont le time to data (délai moyen entre la demande et la disponibilité des données) et le first shot accuracy (taux de données correctes dès leur première version), reflétant l’efficacité des processus et leur capacité à éviter les corrections ultérieures.
De l’autre, la responsabilité de contenu repose sur cinq dimensions essentielles, pilotées par les data-owners : l’intégrité (cohérence et existence des valeurs), la complétude (exhaustivité des enregistrements), la pertinence (adéquation des valeurs aux règles métiers), la fraîcheur (actualisation régulière des données) et l’unicité (absence de doublons). Ces dimensions permettent de s’assurer que les données sont fiables et utilisables.
-
 Delphine CUVELLIER
Delphine CUVELLIERCustoms manager France

-
 Olivier WEIS
Olivier WEISS&OP Business Development Manager

-
 Saad KADIOUI
Saad KADIOUIPartner / Head of IS transformation

Questions-Réponses avec l’Audience
La dernière partie est consacrée aux questions des participants, qui portent sur des enjeux très concrets de mise en œuvre.
-
Acceptation par les métiers
Pour faire accepter la gouvernance sans alourdir les processus, Saad insiste sur le fait qu’il s’agit d’une transformation organisationnelle portée au plus haut niveau (COMEX), et non d’une simple initiative. Cela implique d’adapter les fiches de poste avec l’aide des RH et de définir des objectifs clairs.
-
Rôle du Data Owner à temps partiel
Un participant note que ce rôle est souvent dépriorisé. Saad confirme que c’est un risque réel. La solution réside dans l’intégration de la qualité de la donnée aux objectifs de performance et à l’évaluation de la personne concernée.
-
Reconnaissance des rôles
Les questions confirment la nécessité d’une reconnaissance officielle des statuts de Data Owner et Data Steward dans les fiches de fonction pour que la mission soit prise au sérieux. Delphine ajoute qu’il est souvent plus simple de former un utilisateur de données au métier (la douane, par exemple) que de trouver un data scientist expert du domaine.
-
Fuite de données
En cas d’incident, la réaction doit être proportionnelle au niveau de risque et à la sensibilité de la donnée qui a fuité. Olivier souligne l’importance de mener des revues régulières des droits d’accès pour les retirer lorsque les personnes changent de poste, une pratique souvent négligée.
-
Quantification du ROI
Pour justifier le temps passé sur la qualité des données, Olivier suggère de commencer par évaluer le temps gagné en évitant la consolidation manuelle. Saad complète en affirmant que le ROI se mesure aussi en termes de risques évités (non-conformité, erreurs opérationnelles) et surtout d’opportunités manquées : aucun virage technologique majeur (IA, advanced analytics) n’est possible sans des données de qualité.